How to Debug Serverless Apps?

Debugging serverless apps is different and difficult.
If you have not properly prepared, debugging some requests may be impossible with your current level of instrumentation and tooling.
So what is the best way to debug serverless apps and serverless requests?
The blog post describes how we debug the serverless backend for our SenseDeep Serverless Developer Studio service and what tools we use with our NodeJS serverless apps.
Some of the suggestions here may not be suitable for all sites, but I hope they give you ideas to improve your ability to debug your serverless apps.
But first, some background.
Serverless Computing Changes Things
The way enterprises design, debug and ship applications changed forever when serverless computing arrived on the scene. The introduction of serverless allowed developers to build and ship much faster, which in turn allows them to concentrate on coding rather than maintenance, auto-scaling, and server provisioning.
Serverless is now mainstream and it offers many compelling advantages, but debugging serverless apps is still a tough problem as the required tools have not kept pace.
What is different about serverless debugging?
Debugging a server-based app (monolith) is well understood and assisted by a suite of refined tools that have been created over decades of evolution. Debugging can be performed using IDEs either locally or remotely over SSH and other protocols. Importantly, server state is typically persisted after requests to permit live or after-the-fact inspection and debugging.
Serverless is not so lucky
Serverless is different. It is often more complex with multiple interacting, loosely coupled components. Instead of a monolith, it is more like a spider’s web and consequently harder to follow a single request with no ability for live debugging or setting breakpoints to intercept code execution.
Debugging serverless via remote shell or execution is not possible. Serverless requests are ephemeral and request state is not available after execution. Once a request has been completed, there is no state left behind to examine.
So when a serverless request errors, it often fails silently or any record is buried in a mountain of log data in CloudWatch. You will not be proactively notified and if you are informed by the end-user, finding the failed request is a “needle in a haystack” type of problem.
Furthermore, comprehensive local emulation of cloud environments is either not possible or has severe limitations. As cloud services become more evolved, local emulation is becoming increasingly limited in scope and application.
So we need a different technique to debug serverless compared to server-based app debugging.
Serverless Debugging Technique
The primary means of debugging serverless apps is via detailed, intelligent request and state logging, paired with log management to correlate log data and quickly query to locate events of interest.
Whether your code is under development, is being tested as part of unit or integration tests, or in production, detailed logging is the foundation for you to see and understand what is actually happening in your code for each request.
Detailed, intelligent logging is the foundation for serverless observability.
Observability
Observability is the ability to understand your system’s unknown unknowns. i.e. the ability to understand not just expected errors, but also unforeseeable conditions. It is not enough to just log simple, plain text error messages.
Our understanding of all the possible the failure modes of serverless apps is limited by the extent of our knowledge today. Serverless apps can fail in many surprising ways that we may not yet understand and cannot foresee.
So to meet the debugging needs of tomorrow, you need to log much more information and context than you might realize. Your app must emit sufficient state and information to permit debugging a wide range of unexpected conditions in the future without having to stop and redeploy code.
Fortunately, this is easy to do.
How to Log? Extensively.
Often developers add diagnostic logging as an after thought via sprinkled console.log messages.
console.log("Oops, bad thing happened");
However, using console.log to emit simple messages is almost useless in achieving true Observability. Instead, what is required is the ability to emit log messages in a structured way with extra context that captures detailed request state.
Every time a developer uses
console.logan angel cries in heaven.
In addition to the log message, log events should emit additional context information. To achieve this, the output format must be structured. JSON is an ideal format as most log viewers can effectively parse JSON and understand the context emitted.
For example:
log.error(`Cannot authenticate user`, {user, auth, req});
This would emit something like:
{
"timestamp": "2022-03-26T06:41:59.216ZZ",
"message": "Cannot authenticate user",
"type": "error",
"user": { ... },
"auth": { ... },
"req": { ... },
"stack": [ /* stack trace */ ]
}
There are many log libraries that are capable of emitting structured log context data. For SenseDeep, we use the SenseLogs library which is an exceptionally fast logging library designed for serverless. It has a flexible, simple syntax that makes adding detailed log events easy.
SenseLogs emits log messages with context and stack traces in JSON. It can also be dynamically controlled as to which log messages are emitted at runtime without having to redeploy code.
Here is a mock Lambda which initializes SenseLogs and emits various sample log messages:
const log = new SenseLogs()
exports.handler = async (event, context) => {
log.addTraceIds(event, context)
let body = JSON.parse(event.body)
log.info('Request start', {body, event, context})
log.info('New user login', {user, auth})
log.debug('Queue Stats', {q, backlog})
log.fatal('Unexpected exception with cart', {err, cart})
log.emit('Beta', 'Performance metrics for beta release features', {metrics})
}
SenseLogs emits messages into channels such as info, debug, error. These channels can be enabled or disabled via Lambda environment variables. In this way, SenseLogs can dynamically scale up or down the volume of log data according.
Catch All Errors
It is very important to catch all errors and ensure they are reported. Lambdas should catch all exceptions and not rely on the default Lambda and language runtimes to catch errors. Employing a top-level catch can ensure that the exception report includes request state and correlation IDs.
Dynamic Logging
All log data has a cost and extensive logging can significantly impact the performance of your Lambdas and excessive log storage can cause rude billing surprises. Logging extensive state for all requests is typically prohibitively expensive.
A better approach is to enable a solid baseline of log data and to scale up and/or focus logging when required without redeploying code. This is called Dynamic Logging and it is important to be able to do this without the risk of redeploying modified code.
SenseLogs implements Dynamic Logging by listening to a Lambda LOG_FILTER environment variable. This variable may be set to a list of log channels to enable. By default, it is set to enable the following channels:
LOG_FILTER=fatal,error,info,metrics,warn
If the Lambda LOG_FILTER variable is modified, the next and subsequent Lambda invocations will use the adjusted channel filter settings. In this manner, you can scale up and down the volume and focus of your log messages without redeploying code.
You can use custom channels via log.emit to provide log coverage for specific paths in your code and then enable those channels on demand.
log.emit('feature-1', 'Unexpected condition, queue is empty', { /* state objects */ })
SenseLogs has two other environment variables which give more control over the log messages that are emitted.
- LOG_OVERRIDE provides the list of channels to enable for a limited duration of time before automatically reverting to the LOG_FILTER channel set.
- LOG_SAMPLE provides an additional list of channels to enable for a percentage of requests.
LOG_OVERRIDE is a convenient way to temporarily boost log messages that will automatically revert to the base level of logging when the duration completes. LOG_OVERRIDE is set to a Unix epoch timestamp (seconds since Jan 1 1970) when the override will expire, followed by a list of channels.
LOG_OVERRIDE=1626409530045:data,trace
LOG_SAMPLE is set to a percentage of requests to sample followed by a list of channels to add to the list of LOG_FILTER for sampled requests.
LOG_SAMPLE=1%:trace
See the SenseLogs Documentation for more details.
SenseDeep
You can modify environment variables with the AWS console:
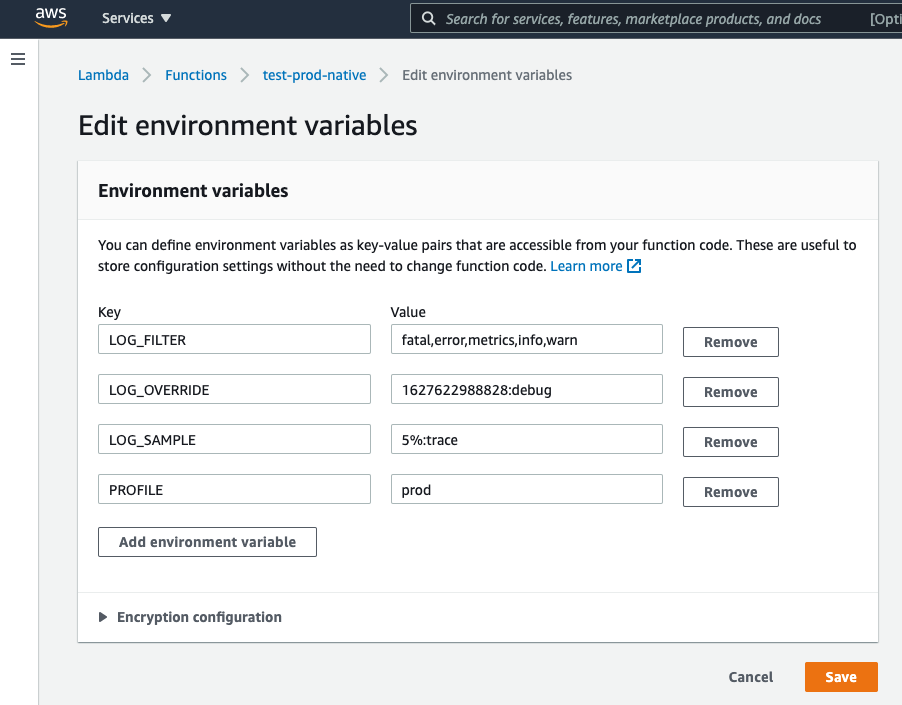
But our SenseDeep serverless developer studio provides a much more convenient interface to manage Lambda LOG_FILTER settings for a single Lambda or for multiple Lambdas.
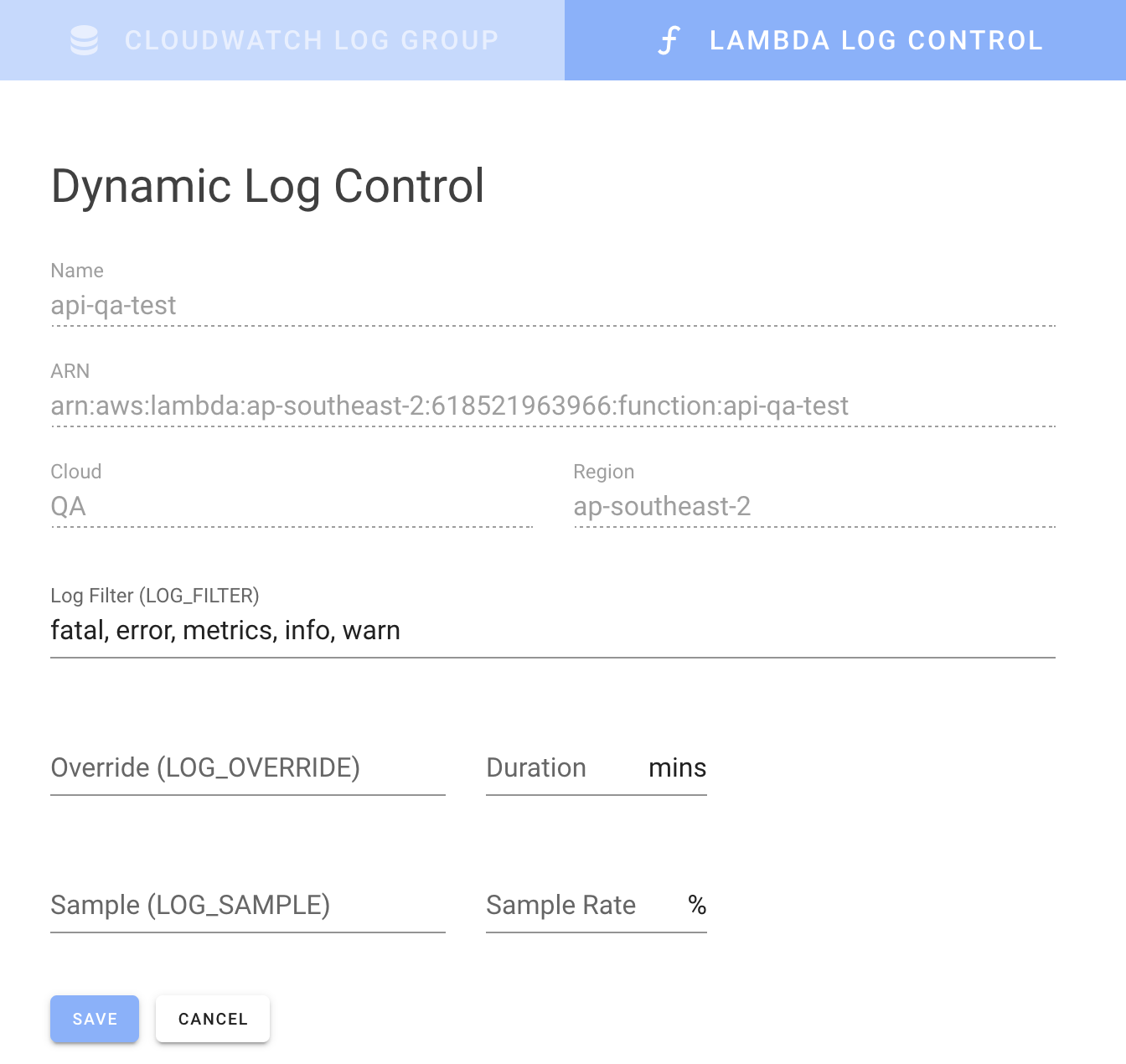
Base Logging
Your serverless apps should emit a good base of request state for all requests.
This should include the request parameters, request body and other high priority state information. The volume of log data should be low enough so that the cost of log ingestion and storage is not a significant burden.
Feature Logging
For critical code modules or less mature code, we include additional logging on custom channels that correspond to each module or feature. This can then be enabled via LOG_FILTER or LOG_OVERRIDE.
LOG_FILTER=fatal,error,info,metrics,warn,feature-1
or
LOG_OVERRIDE=1626409530045:feature-1
Sampled Logging
For a small percentage of requests, we log the full request state so that we always have some record of all the state values. We use a custom SenseLogs channel called complete and we sample those requests at a low percentage rate.
log.emit('complete', { /* additional state objects */ })
LOG_SAMPLE=1%:complete
Correlation IDs
Serverless apps often have multiple Lambda functions or services that cooperate to respond to a single client request. Requests that originate with a single client request may traverse through many services and these services may be in different AWS regions or accounts.
A single request will often traverse through multiple AWS services such as: API Gateway, one more more Lambda functions, Kinesis streams, SQS queues, SNS messages, EventBridge events and other AWS services. The request may fan out to multiple Lambdas and results may be combined back into a single response.
To trace and debug an individual requests, we add a request ID to all our log events. This way we can filter and view a complete client request that flows though multiple Lambda services.
We add the trace IDs by using the SenseLogs API:
log.addTraceIds(event, context)
SenseLogs will extract the API Gateway request ID, Lambda request ID and X-Ray trace ID. SenseLogs will map these IDs to x-correlation-NAME SenseLogs context variables suitable for logging. The following variables are automatically detected and mapped:
- x-correlation-api — API Gateway requestId
- x-correlation-lambda — Lambda requestId
- x-correlation-trace — X-Ray X-Amzn-Trace-Id header
- x-correlation-extended — AWS extended request ID
SenseLogs will define a special variable ‘x-correlation-id’ that can be used as a stable request ID. It will be initialized to the value of the X-Correlation-ID header and if not defined, SenseLogs will use (in order) the API Gateway request or X-Ray trace ID.
SenseLogs also supports adding context state to the logger so you don’t have to specify it on each logging API call. Thereafter, each log call will add the additional context to the logged event output.
Finally we define a client ID that is passed from the end-user so we can track a “user request” through all AWS services that are invoked.
log.addContext({'x-correlation-client': body?.options.clientId})
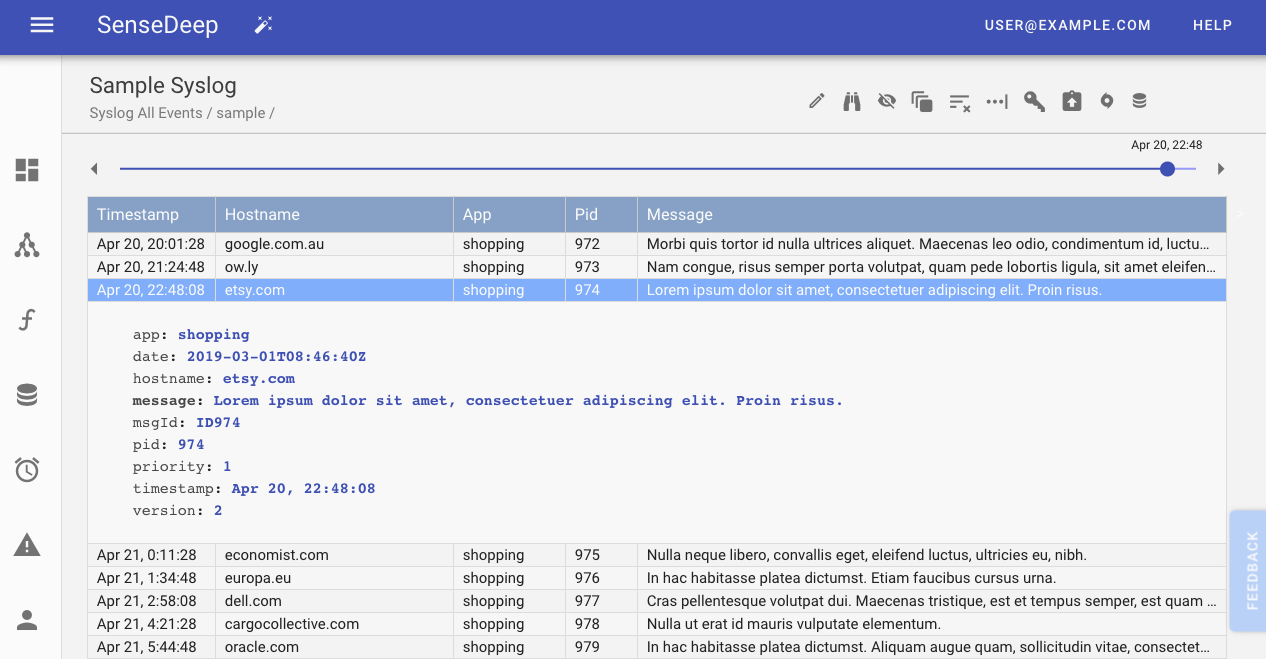
Log Viewing and Querying
Once you have added detailed logging with correlation IDs to your Lambdas, you need an effective log viewer to display and query log events.
CloudWatch just won’t cut it.
For our logging needs, we need a log viewer that can:
- Aggregate not just log streams, but log groups into a unified set of events.
- Aggregate log groups from different AWS accounts and regions.
- Display log events in real-time with minimal latency.
- Instantly query log events to isolate an individual request using correlation request IDs.
- Manage dynamic log control to focus and scale up or down log data as required.
Our product, SenseDeep has such a log viewer that we use to monitor and debug the SenseDeep backend service.
Automated Alarms
Manually monitoring logs for app errors and signs of trouble is not scalable or reliable. An automated alarm mechanism when paired with detailed logging is the ideal platform to provide 24x7 oversight of your serverless apps.
We use such an automated approach. We configure multiple SenseDeep alarms to search for specific flags in log data that indicate errors or potential issues. If an alarm is triggered, an alert will immediately notify the relevant developer with the full context of the app event.
We instrument our code to not only capture and log errors, but also with “asserts” that test expected conditions and will emit log data that will trip alarms if unexpected conditions arise.
Triggering Alarms
To reliably trigger alarms, it is necessary to have a unique property value that the alarm mechanism can detect.
The SenseLogs logging library supports a flagging mechanism where log events to specific log channels can add a unique matchable “flag” to the log data. Alarms can then reliably test for the presence of such a flag in log data.
We use SenseLogs to add property flags for errors and asserts. By default, SenseLogs will add a FLAG_ERROR property for log events error() or fatal().
For other log channels, the flag option can be set to an map of channels, and the nominated channels will be flagged with the associated value string. For example:
new SenseLogs({flag: {warn: 'FLAG_WARN', error: 'FLAG_ERROR', custom: 'FLAG_CUSTOM'})
log.warn('Storm front coming')
This will emit:
{
"message": "Storm front coming",
"FLAG_WARN": true
}
We then create a SenseDeep alarm to match FLAG_ERROR and other FLAG_* patterns.
SenseDeep Alarms
We configure alarms for generic errors and exceptions as well as specific asserts and state conditions.
CloudWatch Alarms do not have the ability to efficiently monitor log data for specific log data patterns.
Fortunately, SenseDeep was built for this purpose.
SenseDeep developers create alarms to detect flagged errors when errors and unexpected conditions are encountered.
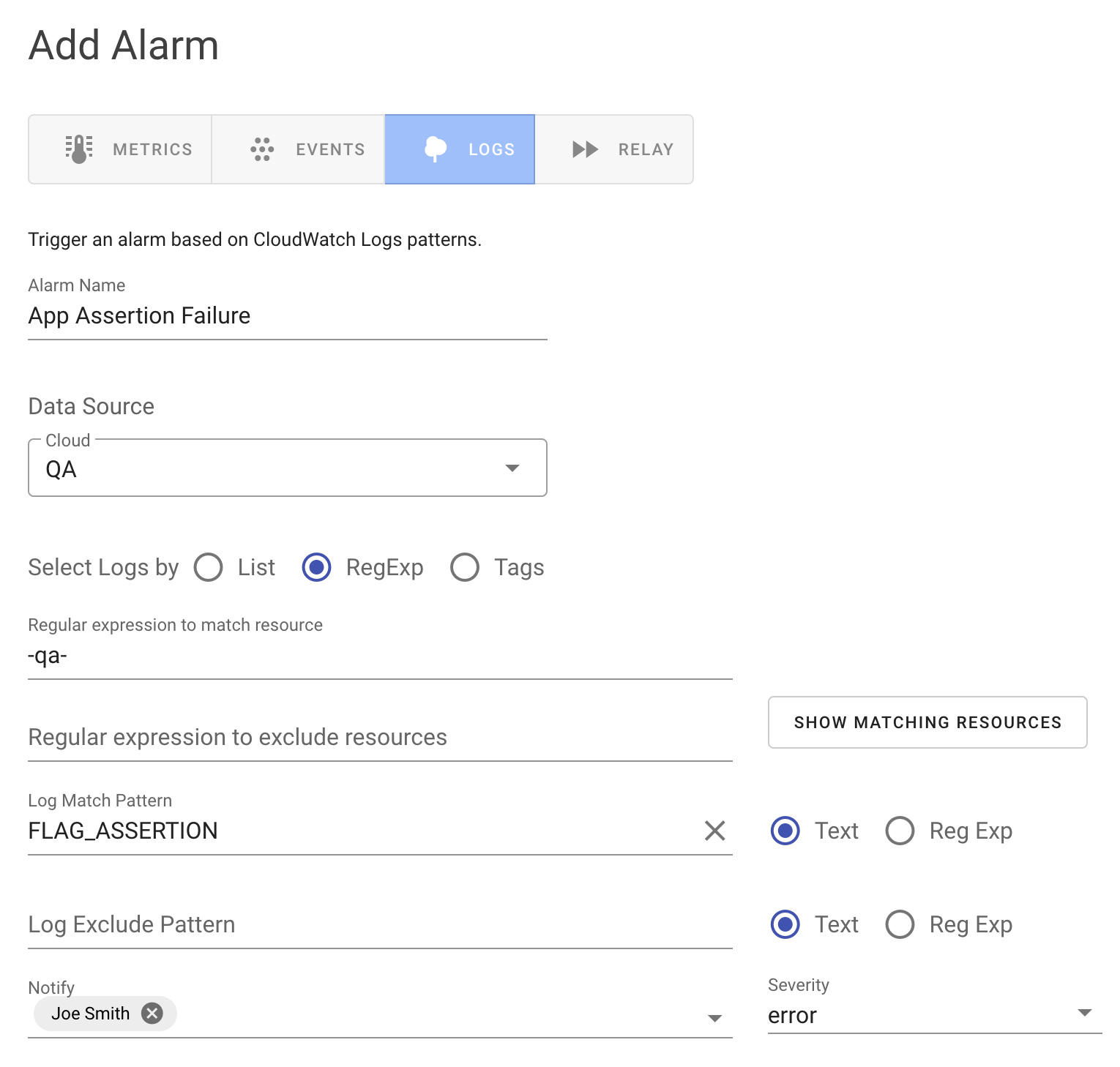
As SenseDeep ingests log data, it runs configured alarms to match app errors in real-time.
Alert Notifications
When an alarm triggers it generates an alert to notify the developer via email, SMS or other notification means.
The alert contains the full details of the flagged condition.
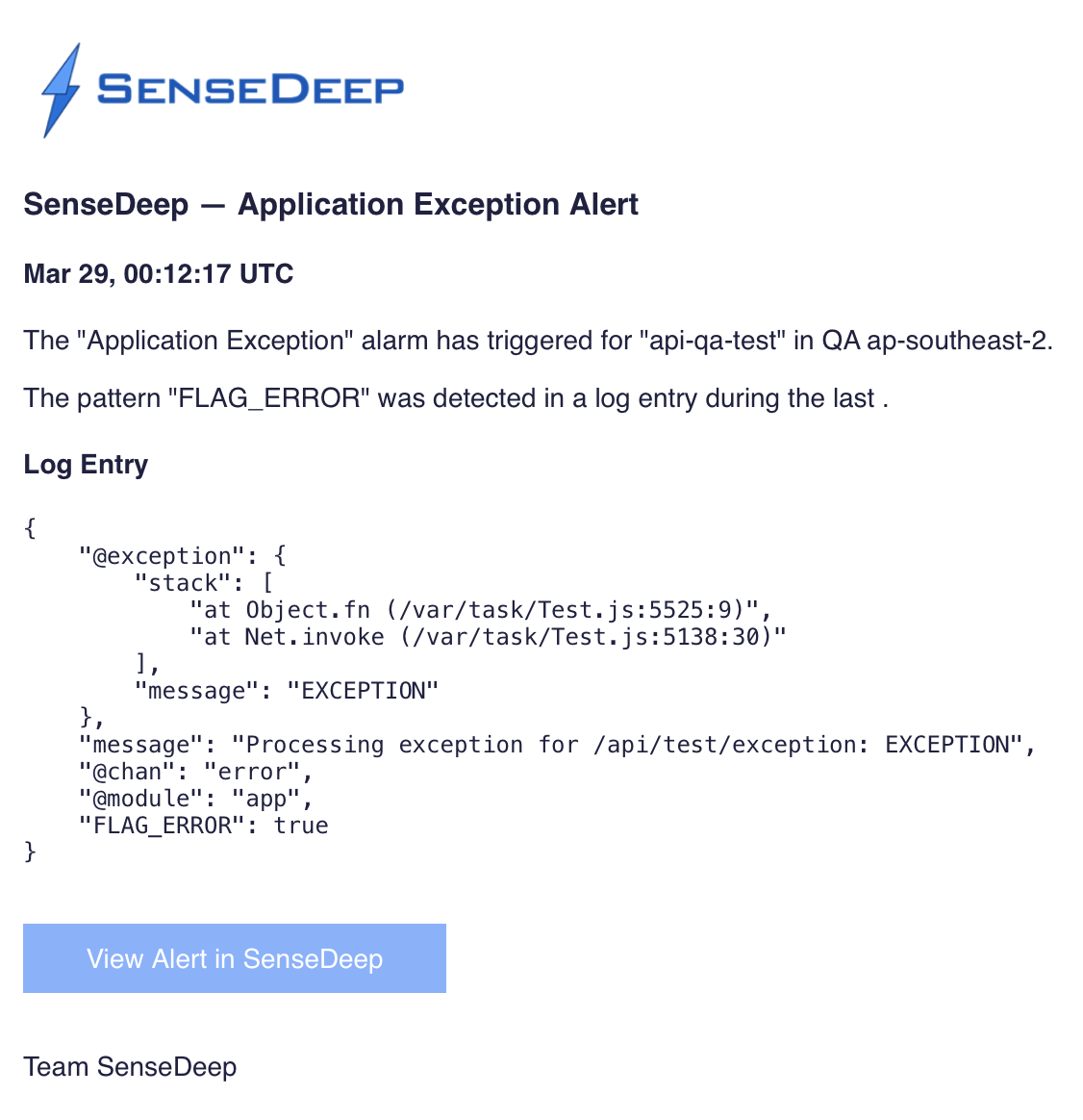
Clicking on the notification link will launch SenseDeep and display full details of the alert that triggered the alarm.
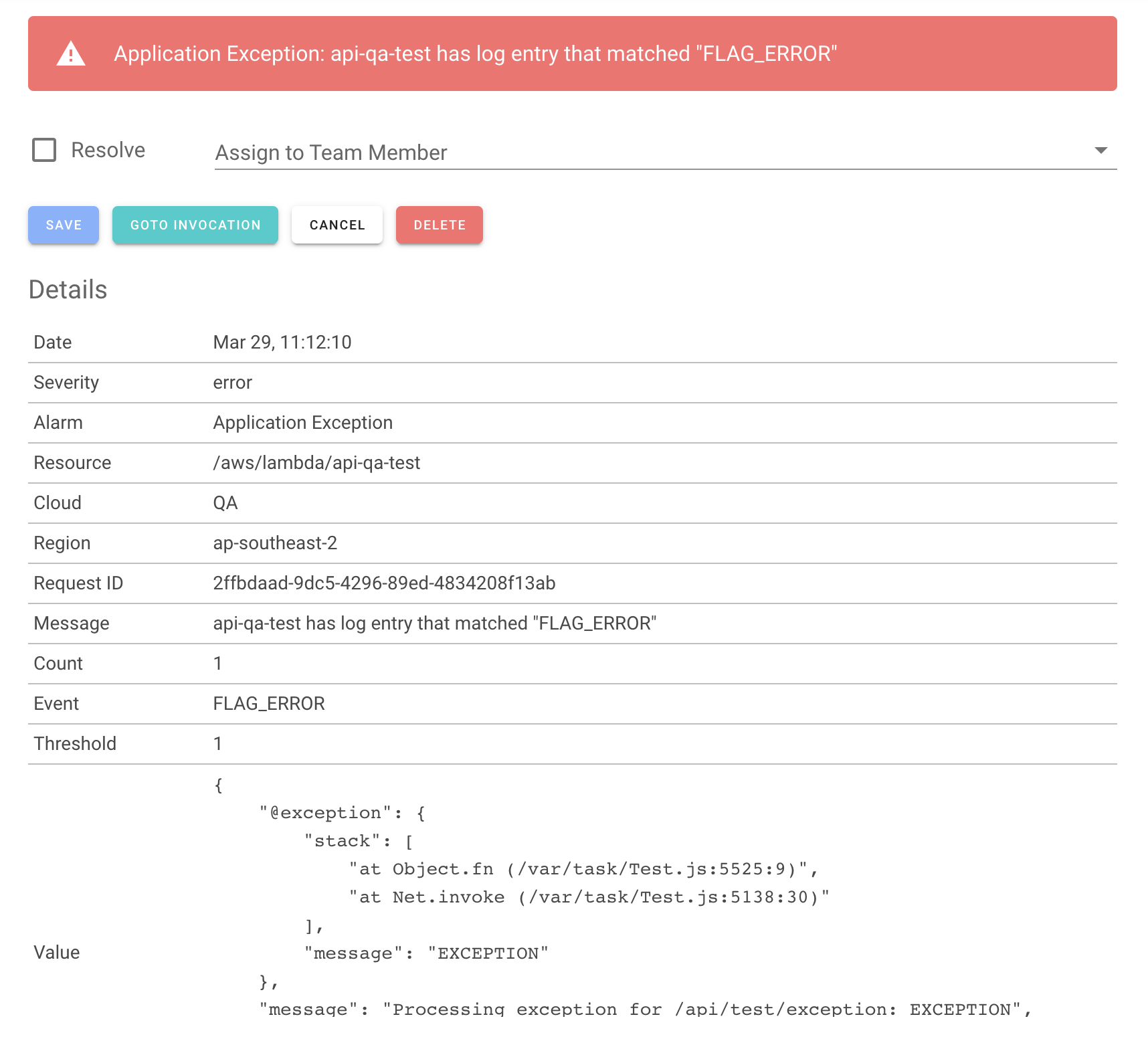
To see the log entries for the invocation, click on Goto Invocation.
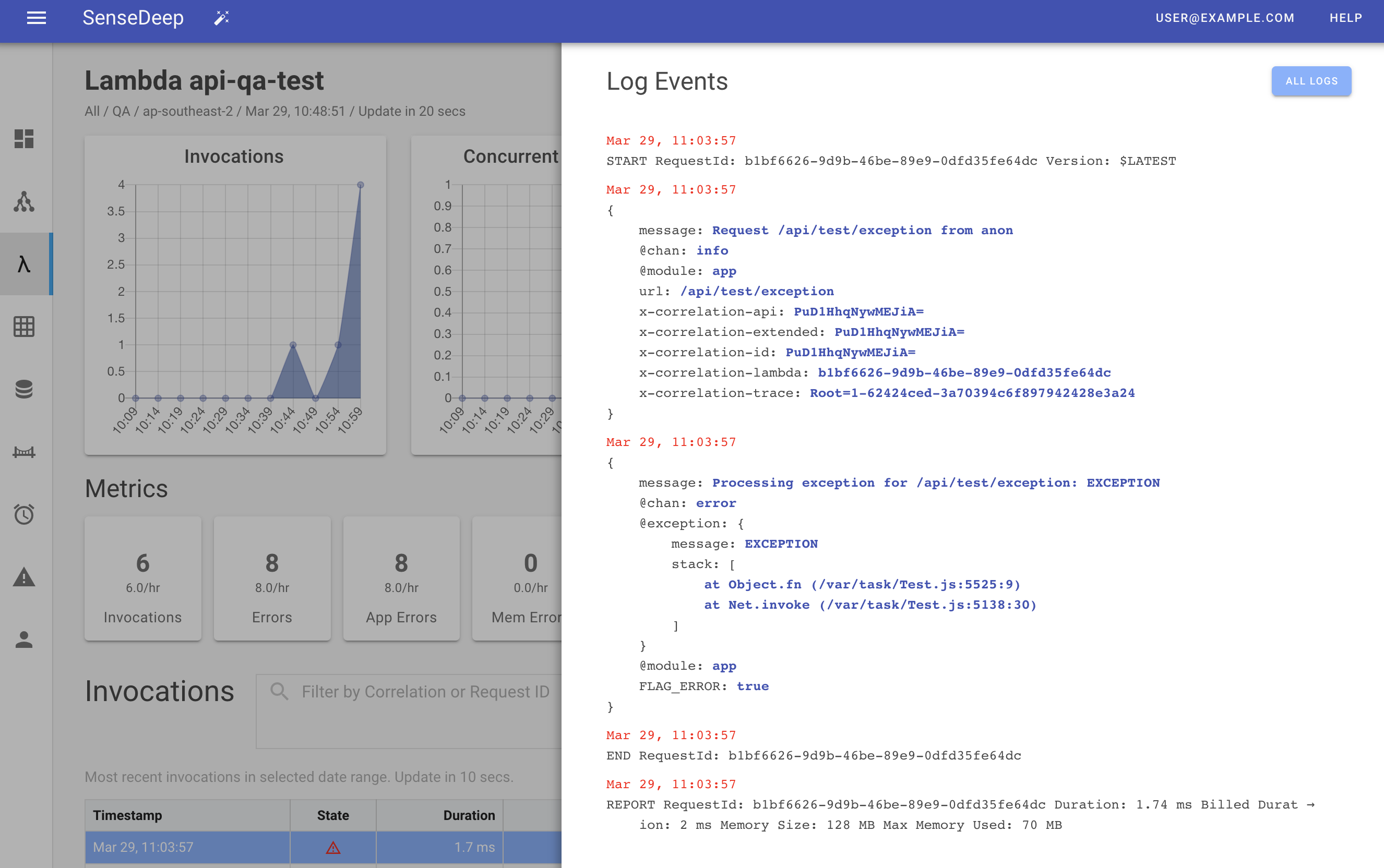
If you want to see the preceding or subsequent log entries, click All Logs which will launch the log viewer homed to the invocation log data.
Serverless Goals
Using this serverless debugging pattern, we can detect problems early, typically before users are even aware of an issue.
The automated monitoring offloads the burden of “baby-sitting” a service and gives developers tools needed to ensure their apps are performing correctly.
CloudWatch Insights and X-Ray
You may wonder if you can use the native AWS services: CloudWatch and Xray to implement this serverless debugging pattern.
Short answer, you cannot.
CloudWatch does not aggregate log streams or groups. It is slow and only offers primitive query capabilities.
CloudWatch Insights does have the ability to search for correlation IDs in logs in a single region. But it is very, very slow and you cannot then see the request in context with the requests before or after the event. CloudWatch Insights is most useful for custom one-off queries, but not for repeated debugging efforts.
CloudWatch alarms cannot trigger alerts based on log data patterns. You can pair it with CloudWatch Insights, but this is a slow one-off solution and does not scale to process all log data for matching events.
Similarly, X-Ray has many good use cases, but because it only samples 1 request per second and 5% of additional requests, it cannot be used to consistently debug serverless applications. It is great for observing complete outages when an entire service or component is offline, but not for failing individual requests.
References
- SenseDeep Serverless Developer Studio
- SenseLogs Logging Library
- Fast Logging with SenseLogs
- Dynamic Log Control for Serverless
Try SenseDeep
Start your free 14 day trial of the SenseDeep Developer Studio.

Messages are moderated.
Your message will be posted shortly.
Your message could not be processed at this time.
Error: {{error}}
Please retry later.
{{comment.name || 'Anon'}} said ...
{{comment.message}}