Data Modeling for DynamoDB Single Table Design

The DynamoDB database provides an easy to configure, high-performance, NoSQL database with low operational overhead and extreme scalability. It appeals to developers with OLTP applications requiring a simple serverless database or those needing the utmost in scalability.
More recently, best practices have evolved around DynamoDB single-table design patterns where one database table serves the entire application and holds multiple different application entities. This design pattern offers greater performance by reducing the number of requests required to retrieve information and lowers operational overhead. It also greatly simplifies the changing and evolving of your DynamoDB designs by uncoupling the entity key fields and attributes from the physical table structure.
The recent rise of DynamoDB single-table designs is due to the tireless work of educators like Alex DeBrie and Rick Houlihan to help get a better understanding of how to model DynamoDB data in a single-table design and the availability of modeling tools like the SenseDeep DynamoDB Studio.
Why OneTable?
DynamoDB is a great NoSQL database that comes with a steep learning curve, especially with single-table designs. However, developers find that modeling, defining and expressing DynamoDB single-table designs can be difficult at first.
The OneTable library builds upon recent modeling tools and provides a more natural way to define DynamoDB single-table designs and entity definitions without obscuring any of the power of DynamoDB itself.
So how does the process of using OneTable for single-table designs differ from the traditional approach?
The first key difference is that OneTable uses a schema to define the application entities, keys, attributes and table indexes. Having your application indexes, entities and keys defined in one place is much better than scattering these definitions throughout your application.
For example, here is a schema that defines two entities: Account and User and the primary index and one GSI.
OneTable Schemas
const MySchema = {
indexes: { primary: { hash: 'pk', sort: 'sk' } },
models: {
Account: {
pk: { value: 'account#${name}' },
sk: { value: 'account#' },
name: { type: String, required: true },
},
User: {
pk: { value: 'account#${accountName}' },
sk: { value: 'user#${email}', validate: EmailRegExp },
accountName: { type: String },
email: { type: String, required: true },
},
Post: {
pk: { value: 'post#${id}' },
sk: { value: 'user#${email}', validate: EmailRegExp },
id: { type: String },
message: { type: String },
email: { type: String },
}
},
version: '0.1.0',
format: 'onetable:1.0.0'
}
Key Management
Single-table designs overload the partition and sort key values by using key prefix labels. In this way, multiple entities can be safely stored and reliability retrieved via a single-table.
OneTable centralizes key management for your queries and database operations. The entity partition and sort keys in OneTable can be ordinary attributes. However, it better to uncouple your keys by defining them as template strings that are calculated at run-time based on the values of other attributes. OneTable uses the value property to specify the template which operates just like a JavaScript string template.
These OneTable techniques effectively uncouple the logical entity keys from the physical table key names and make changing and evolving your single-table design much easier.
The DynamoDB Single-Table Design Process
The single-table design process is iterative and consists of the following steps:
Determine the application entities and relationships.
Determine all the access patterns.
Determine the key structure and entity key values.
Codify the design as a OneTable schema.
Create OneTable migration scripts to populate the table with test data.
Prototype queries to satisfy each of the access patterns.
Repeat and refine.
Good key design will support item collections where a single request can be used to retrieve multiple related items and thus in practice implement a “join” between different entities. Consequently, work hard to create item collections wherever possible and avoid “joining” entities in your application code after multiple requests to retrieve the data.
Create an Entity / Relationship Diagram (ERD)
Before even thinking of writing code or creating a database table, ensure you have determined all your application data entities and their relationships. You should document this as an Entity Relationship Diagram (ERD).
For example: an ERD for a trivial blog application with entities for Accounts, Users and Blog Posts.
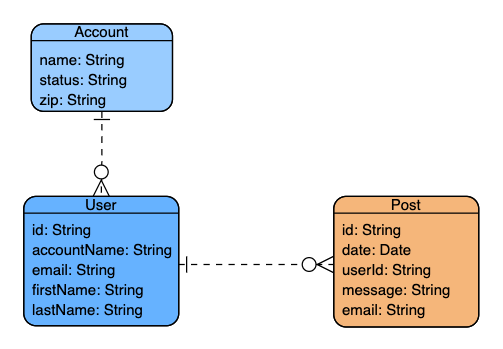
Your ERD should identify all essential entities and their constituent attributes and relationships.
You need to classify the relationships between your entities as being either one-to-one, one-to-many or many-to-many. In the example above, one account can have many users who can have many blog posts.
Determine Access Patterns
Next, enumerate and document all the access patterns to retrieve or manipulate your data. The access patterns should describe the query to implement and the entity attributes required to retrieve the item.
Ensure you consider access for user interfaces, APIs, CRUD for all entities and don’t forget required maintenance operations.
Your access pattern list should describe the entities and attributes queried and the required key fields.
For Example:
| Access Pattern | Query | Entities Retrieved |
|---|---|---|
| Get account | Get account where “name” == NAME | Account |
| Get user by email | Get user where “email” == EMAIL | User |
| Find users for account | Find users where “accountName” == ACCOUNT_NAME | Users, Account |
| Find posts for a user | Find posts where “email” == EMAIL | Posts, User |
| … | … |
It can sometimes be helpful to split your access patterns into real-time and batch access groupings. The batch group may need to utilize the DynamoDB scan() method.
Design Key Structure
Once you have defined all your access patterns, you can design your primary and secondary keys. This is inherently an iterative process as there are often several viable options when selecting an entity’s keys.
The goal is to identify the required indexes and create a key structure that will satisfy all the identified access patterns via efficient queries using as few indexes as possible.
This is achieved by overloading key contents and careful selection of key prefix labels.
Physical Keys
The physical database primary and secondary keys should have generic names like pk and sk for partition and sort key. For secondary indexes, they should have equally generic names like gs1pk and gs1sk. These physical keys are “overloaded” by multiple entities that use the same physical key attributes for multiple access patterns. This is achieved by using unique prefix labels for key values to differentiate the items. In this way, a single index can be used to query multiple entities in different ways.
Logical Keys
All database items will have a logical primary partition (hash) key with an optional sort key. Some item entities may also have one or more secondary keys to support additional access patterns.
It can be tempting to set your primary key to be a simple unique entity field. For example: you may initially select your User partition key to be the user’s email address. While this may be a solid choice in terms of distribution of key values, there may be better choices that are both unique and facilitate retrieval of item collections where you can fetch multiple related items with a single request.
For example, consider the “Find users for account” access pattern. It would be useful to retrieve the users and the account at the same time. If the User primary key is simply the user’s email address, then you will have to perform a separate request to get the owning account and then join them in your application code.
However, if the User’s primary partition key is set to the account name and the sort key is set to user’s email address, then a query using a partition key set to the account name and an empty sort key will retrieve an item collection of all the users and the account in one request.
Key Design Strategies
The general strategy for key design is:
Select a primary partition key with a high cardinality that will distribute load over all partitions and avoid hot keys.
Use the same partition key for retrieving related items required for a single access pattern and create a set of sort keys to differentiate between the items.
Select your sort key values to support multiple access patterns by using concatenated sub-fields. This strategy is similar to nested “Russian Dolls” in that you can query different levels via queries using the
begins_withoperator. For example: in a shopping cart app, you could specify the leading prefix to get orders by account, user or product.
Orders by account: order#${accountId}
Orders by user: order#${accountId}#${userId}
Orders by product: order#${accountId}#${userId}#${productId}
Use the sort key with a query limit limit to determine how many items in the collection to read (use the sorted or reversed sort order)
Don’t store unique attribute values in the keys themselves. Rather project the values of other attributes via OneTable template strings. This uncouples your keys from the entity attributes and will give you more flexibility to evolve your design in the future.
Handle post-processing and data aggregation needs separately via DynamoDB streams. This may simplify your key structure by handling these use cases separately and may potentially avoid the need for real-time use of the costly DynamoDB
scanoperation.
Helpful Entity Relationship Strategies
Modeling relationships including one-to-many and many-to-many relationships is the heart of most data models. As a NoSQL database, DynamoDB does not join tables via foreign keys. Instead, you must model your data in such a way so that data is “pre-joined” by design to enable your access patterns.
There are several strategies to implement item relationships.
Adjacency List. The adjacency list pattern is ideal for modeling one-to-many relationships. With this pattern, target items use the same partition key but use different sort keys or partial sort-keys. Retrieving items using only the partition key with an empty or partial sort key will retrieve the entire collection of items or a suitable subset.
Reverse Secondary Index. You can model many-to-many relationships by using the adjacency list strategy (1) and add a secondary index that has the partition key and sort key reversed. In this manner, you can follow the many-to-many relationship in either direction by using either the primary or secondary index.
Denormalization. You can denormalize related items by including them as a complex attribute. The attribute can be either a list or map with the target items. This strategy works well for smaller item sets that are not updated often. OneTable makes this particularly easy by marshaling data to and from JavaScript arrays and objects automatically. Remember DynamoDB enforces a 400KB limit on items.
Duplication. Similar to (1) you can simply duplicate the referenced item. This can work well if the data is not extensively duplicated and if the data is not updated regularly. i.e. works best for read-only constant data.
Simple reference. A last resort is to include the primary key of the target item as an attribute. This then requires a second query to retrieve the target item. With OneTable, you only need to store the logical ID attributes of the item and not the physical key values.
Using these strategies, consider each access pattern and design your keys and then add to your access patterns table.
| Access Pattern | Query | Entities | Index | Hash Key | Sort Key |
|---|---|---|---|---|---|
| Get account | account where “name” = NAME | Account | Primary | account#NAME | |
| Get user by email | user where “email” = EMAIL | User | GS1 | user#EMAIL | |
| Find users for account | users where “accountName” = ACCOUNT_NAME | Users, Account | Primary | account#NAME | |
| Find posts for a user | posts where “email” = EMAIL | Posts, User | GS1 | user#email | begins(post) |
Using the updated access pattern table, we can extract the key structure for each of the entities.
| Entity | Hash Key | Sort Key | GSI-1 hash | GSI-1 sort |
|---|---|---|---|---|
| Account | account#NAME | account# | ||
| User | account#NAME | user#EMAIL | user#EMAIL | account#NAME |
| Post | post#EMAIL | post#ID | user#EMAIL | post#ID |
Create a OneTable Schema
Your design can then be coded as a OneTable schema by creating a “model” for each entity. List each of the entity attributes and identify the primary key for each entity.
const MySchema = {
version: '0.1.0',
format: 'onetable:1.0.0',
indexes: {
primary: {
hash: 'pk',
sort: 'sk',
},
gs1: {
hash: 'gs1pk',
sort: 'gs1sk',
}
},
models: {
Account: {
pk: { value: 'account#${name}' },
sk: { value: 'account#' },
name: { type: String },
address: { type: String },
},
User: {
pk: { value: 'account#${accountName}' },
sk: { value: 'user#${email}' },
gs1pk: { value: 'user#${email}' },
gs1sk: { value: 'account#${accountName}' },
accountName: { type: String },
email: { type: String },
},
Post: {
pk: { value: 'post#${email}' },
sk: { value: 'post#${id}' },
gs1pk: { value: 'user#${email}' },
gs1sk: { value: 'post#${id}' },
id: { type: String, lsid: true },
date: { type: Date },
message: { type: String },
email: { type: String },
}
},
}
Create your DynamoDB Database
You are now finally ready to actually create your DynamoDB database. Use Cloud Formation, the Serverless Framework, CDK or equivalent to specify and create your database. Don’t use the console to create production resources.
You should create a single table with a generic primary key and any additional secondary indexes.
The example below depicts a Serverless Framework resource file that creates a database with one GSI with the key names: pk, sk, gs1pk and gs1sk.
resources:
Resources:
MyDatabase:
Type: AWS::DynamoDB::Table
DeletionPolicy: Retain
Properties:
TableName: BlogDatabase
AttributeDefinitions:
- AttributeName: pk
AttributeType: S
- AttributeName: sk
AttributeType: S
- AttributeName: gs1pk
AttributeType: S
- AttributeName: gs1sk
AttributeType: S
KeySchema:
- AttributeName: pk
KeyType: HASH
- AttributeName: sk
KeyType: RANGE
GlobalSecondaryIndexes:
- IndexName: gs1
KeySchema:
- AttributeName: gs1pk
KeyType: HASH
- AttributeName: gs1sk
KeyType: RANGE
Projection:
ProjectionType: 'ALL'
BillingMode: PAY_PER_REQUEST
Provision your Database using Migrations
Once the physical database is created, the next step is to create some test data so that queries can be prototyped to test the access patterns.
You can use the OneTable CLI to apply your schema and populate your database with test data. The CLI applies discrete changes to your database via “migrations”. These are reversible scripts that can quickly and easily make changes to the structure and data of your database.
Conventional wisdom for DynamoDB has been to be that changing a DynamoDB design is “extremely difficult” and you want to avoid it at all costs. However, with single-table designs that uncouple your logical and physical keys, and with reversible migrations, you can make small and large changes to your live production database without downtime.
The ability to evolve your DynamoDB database may be the most important benefit of single-table designs.
Install the OneTable CLI via:
npm i onetable-cli -g
Make a directory for your migrations in your project and create a migrate.json with your DynamoDB OneTable configuration.
{
name: 'your-dynamo-table-name',
endpoint: 'http://localhost:8000',
schema: './schema.js',
}
The endpoint property specifies the local DynamoDB endpoint. To connect to DynamoDb in a real AWS account, read the OneTable CLI article for details.
Generate your first migration:
onetable generate
Migrations are Javascript files that contains up and down methods that are invoked to upgrade or downgrade the database. Edit the up and down methods to create and remove the test data.
Here is an example migration to create an Account, User and two posts.
export default {
version: '0.0.1',
description: 'Initial migration',
schema: Schema,
async up(db, migrate) {
let account = await db.create('Account', {
name: 'Acme Rockets',
})
let user = await db.create('User', {
email: 'user1@example.com',
accountName: account.name,
})
await db.create('Post', {
email: user.email,
message: 'Post 1',
user: user.email,
})
await db.create('Post', {
email: user.email,
message: 'Post 2',
user: user.email,
})
},
async down(db, migrate) {
let items
do {
// A rare case where scan is justified!
items = await db.scanItems({}, {limit: 100})
for (let item of items) {
await db.deleteItem(item)
}
} while (items.length)
}
}
Apply the migration via the command:
onetable up
This will create the test data according to the defined schema.
After testing, you can at anytime reset the database with new test data via:
onetable reset
Read more about the CLI at OneTable CLI.
Queries
When coding your queries to implement and test the access patterns, you can filter the items and attributes returned by using DynamoDB filter and projection expressions.
Filter expressions are applied by DynamoDB after reading the data. They are thus not a substitute for a well designed key structure and query. But filter expressions are useful to select items based on matching non-key attributes.
Projection expressions select the attributes to return after filtering the items. A projection expression can reduce I/O transfer time especially if the item is large.
OneTable makes both filter expressions and projection expression easy to use via the where and fields options. For example:
let accounts = await Account.find({}, {
where: '${balance} > {100.00}'
fields: ['id', 'name', 'balance', 'invoices']
})
Fetching Item Collections
To fetch an item collection, use the queryItems API and parse the results. Then use the groupByType if you want the returned items to be organized into groups. For example:
let items = await table.queryItems({pk: 'account:AcmeCorp'}, {parse: true})
items = db.groupByType(items)
let users = items.Users
let products = items.Products
Working Samples
We have several pre-built working samples that demonstrate OneTable.
- OneTable Overview Sample — A quick tour through OneTable.
- OneTable Migrate Sample — how to use OneTable Migrate and the Migrate CLI.
- All OneTable Samples
Conclusion
This completes the journey to design your single-table DynamoDB database.
As we learn more about single-table design patterns and develop better data modeling tools and libraries, the performance and operational benefits of single-table designs outweigh their initial, apparent complexity. When considering the greatly improved ability to evolve and change your DynamoDB data design, single-table patterns emerge as the preferred option over multi-table designs for most DynamoDB implementations.
At SenseDeep, we’ve used DynamoDB, OneTable and the OneTable CLI extensively with our SenseDeep serverless developer studio. All data is stored in a single DynamoDB table and we extensively use single-table design patterns. We could not be more satisfied with DynamoDB implementation. Our storage and database access costs are insanely low and access/response times are excellent and we’ve been able to extensively evolve our design in production without downtime.
Please try our Serverless developer studio SenseDeep.
Read more about OneTable and the OneTable CLI and the DynamoDB Checklist.
References
- DynamoDB Checklist
- DynamoDB Best Practices
- Relational Modeling in DynamoDB by AWS
- Database Design Lab
- DynamoDB Many Relationships
Links
Try SenseDeep
Start your free 14 day trial of the SenseDeep Developer Studio.

Messages are moderated.
Your message will be posted shortly.
Your message could not be processed at this time.
Error: {{error}}
Please retry later.
{{comment.name || 'Anon'}} said ...
{{comment.message}}