Effective logging is an essential foundation for any cloud application or service. However, just doing print statements of plain text does not lead to effective logging nor the ability to quickly diagnose issues.
This checklist is for serverless cloud services and apps with a focus on AWS. It is a simple, aspirational checklist, and by no means addresses all the possible issues. It is not expected that all sites can or should achieve all items.
However, we hope the checklist may trigger some ideas for you when designing or improving your logging infrastructure.
We try to keep the list tight and focused, but please comment if you have an item that you think we should add to the list.
## Contents - [Centralized Your Logs](#centralized-your-logs) - [Selecting the Right Logging Service](#selecting-the-right-logging-service) - [Logging Formats](#logging-formats) - [What to Log](#what-to-log) - [What Not to Log](#what-not-to-log) - [Dynamic Logging](#dynamic-logging) - [Metrics and Monitoring](#metrics_and_monitoring) - [Alarms](#alarms) - [Governance](#governance) - [Security](#security)
## **Centralize Your Logs** - [ ] Centralize the storage and processing of all log and metric data for your entire service. This greatly simplifies your log management, analysis and correlation tasks. - >Centralized log management is where you aggregate logs from all servers, applications, services and devices into a single location. The centralized location enables a single point of management for for access, control, storage, monitoring, alerting and analysis. ## **Select the Right Logging Service** - [ ] Select a logging service that is strong on the basics: low complexity, fast capture, secure storage, easy log viewing and powerful queries. Pretty graphs come last. Many enterprise logging solutions are way too complex for the need and usability comes in a poor second to a swamp of features. Consider the [SenseDeep Free Plan](https://www.sensedeep.com) if on a small budget. - [ ] Select a logging provider that can provide fast log capture and ingestion. Many log vendors impose a several minute delay before log data is available. Some "near real-time live-tail" viewing really means "wait 5 minutes". - [ ] A fast UI and UX experience is an essential foundation. Avoid log viewers that are slow to load or traverse log events. Powerful queries do not compensate for a slow viewer. HowTo: Consider the [SenseDeep AWS CloudWatch Logs Viewer](https://www.sensedeep.com/blog/posts/stories/sensedeep-a-better-cloud-watchlogs-viewer.html). - [ ] Select a logging service that can aggregate logs to correlate issues across all your services even if they are in different regions or cloud accounts. ## **Logging Formats** - [ ] Emit log data in a machine readable format. Don't emit plain text strings. Instead use JSON or key/value pairs to emit structured data (really, just use JSON). - [ ] Use consistent logging formats wherever possible across all your services. - [ ] Use a fast, simple logging library that makes it easy for developers to instrument their code with low effort. Consider [SenseLogs](https://www.npmjs.com/package/senselogs). - [ ] Define and document your logging schema to standardize on emitted attributes. ## **What to Log** - [ ] Capture relevant, unique log information for all services or components that participate in request processing or can potentially impact your service. - [ ] Log with rich structured context including: timestamp, type of message, application name, user/account, region/location, client/agent, UI-page, and timing information. - >To be "Observable" you need to log information sufficient for future log diagnosis needs. But be mindful of the total volume of logged information. Too much data can obscure critical information. - [ ] Emit high cardinality fields such as user IDs and request IDs that can be used to correlate related events across logs in context. - [ ] Use unique messages that can be back-tracked to code. Consider adding source file/line to log messages. - [ ] Log suspicious input validation errors and increased authentication and validation error rates. - [ ] Log authentication failures including the source IP and identifying client information. - [ ] Measure and log the elapsed time for key operations (from the user's perspective). - [ ] Log database "slow queries" to sample which queries are slowest for your system. ## **What Not To Log** - [ ] Do not emit secrets such as passwords, keys, access tokens, session identifiers. - [ ] Do not emit personally identifying information or health related information. - [ ] Do not emit bank account, financially critical or credit card info without anonymization. - [ ] Do not emit IP addresses or internal endpoints. - [ ] Do not emit database connection strings or internal file paths. - [ ] Don't log redundant information -- be lean. ## **Dynamic Logging** - [ ] Have the ability to enable in-depth logging for specific dimensions such as: accounts, users or requests without redeploying code. HowTo: [Dynamic Logging](https://www.sensedeep.com/blog/posts/stories/dynamic-serverless-log-control.html). - [ ] Have the ability at runtime to enable or disable logging, or increase or decrease the verbosity of messages on a per service or code module basis. - [ ] Have a system where you can enable full debug logging for specific requests or users without having to redeploy code. - [ ] Log the full request path for a small percentage of requests say 1-2% at all times. This greatly aids diagnosing system wide outages or transient outages. ## **Metrics and Monitoring** - [ ] Decide and document your key performance metrics and focus on them. Consider: system availability, request latency, service throughput, available capacity, worst case response times and critical error indicators. - [ ] Emit metrics that describe the end user response times and experience. - [ ] Emit metrics for all key service, application and system errors. - [ ] Emit performance metrics durations of all service impacting actions. - [ ] Emit key security metrics such as increased authentication failures and request validation failures. - [ ] Monitor cloud resource utilization such as AutoScale cluster size and serverless peak instance count. Monitor associated cloud costs with alarms for when key monthly spend limits are crossed. - [ ] If logging a high volume of data, consider having a separate log group/stream for metrics so they can be efficiently extracted and monitored. ## **Alarms** - [ ] Automate your service monitoring with alarms and notifications. - [ ] Enable proactive alerts for top level service anomalies. - [ ] Be able to spot anomalies by extracting trend data from the metrics and logs. - [ ] Setup alerts for when request rates drop suddenly as it may indicate an outage. - [ ] Be able to automatically alert based specific metrics or log conditions. - [ ] Where possible, invoke automated corrective actions based on alarms. - [ ] Employ a simple, clear, top-level dashboard that focuses on the overall status of your service and key performance indicators. ## **Governance** - [ ] Understand your mandated compliance requirements for log retention. - [ ] Manage log retention times for all logs in all regions. Keeping logs forever can be very costly. AWS can scatter logs in regions you thought were not active (CloudFront). - [ ] Retain logs so that a security audit can fully diagnose historical advanced persistent threats. ## **Security** - [ ] Ensure log data is stored securely and encrypted in-transit and at rest. - [ ] Encrypt log data at rest with appropriate encryption AES-256-bit not MD5 or SHA1. - [ ] Ensure log data cannot be tampered with or spoofed in-transit or at rest. - [ ] Ensure you can quickly correlate events across services to see the root cause of active threats. - [ ] Repeat: Do not log secrets or access tokens. Many sites have been hacked because of poorly secured backup logs that contain secrets. ## Keep Iterating Most of all, keep improving your logging infrastructure. Logging is a balance between capturing enough data and ingesting too much. If you start with centralized logging and emitting structured log data in the right format, you'll be on the right path to achieving "Observability" for your service and applications.
Learn More About SenseDeep
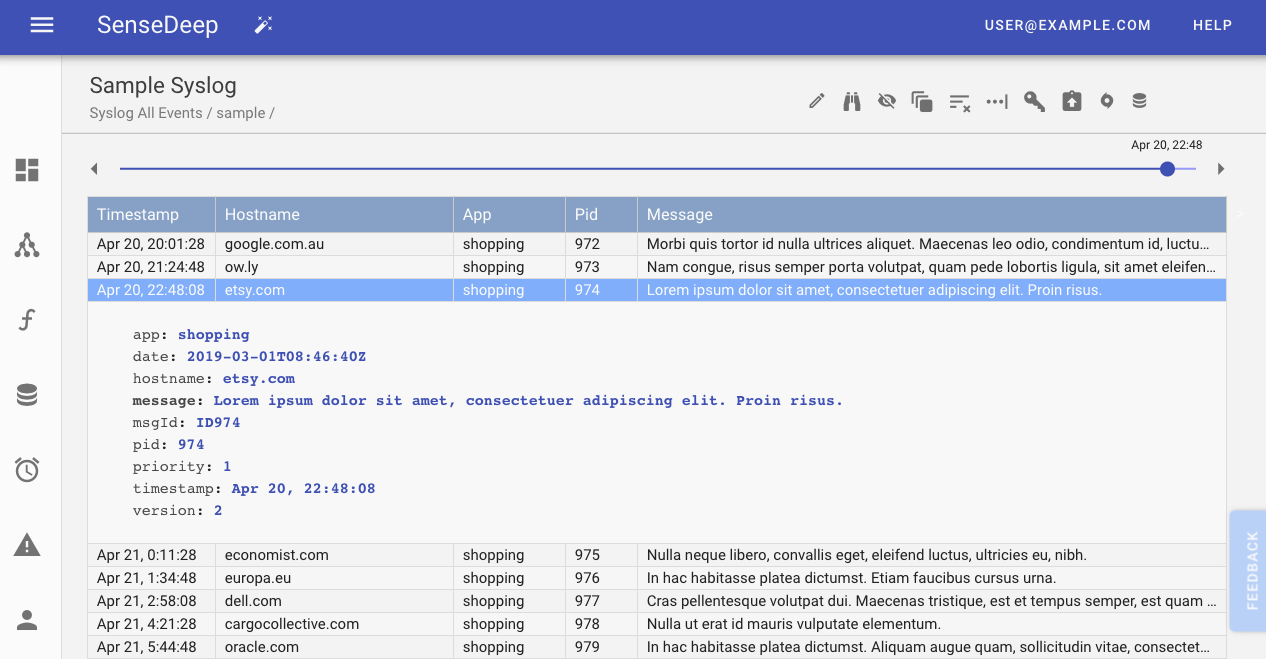
While developing cloud services at SenseDeep, we wanted to use CloudWatch as the foundation for our logging infrastructure, but we needed a better, simple log viewer and analysis tool that supported fast smooth scrolling and better log queries and data presentation.
So we created SenseDeep, a serverless developer studio. It includes a blazing fast CloudWatch logs viewer that transparently downloads and queries log events in your browser for immediate viewing. It offers smooth scrolling, live tail and powerful structured queries. It understands structured log data for intelligent presentation and queries.
This web site uses cookies to provide you with a better viewing experience. Without cookies, you will not be able to view videos, contact chat or use other site features. By continuing, you are giving your consent to cookies being used.


Messages are moderated.
Your message will be posted shortly.
Your message could not be processed at this time.
Error: {{error}}
Please retry later.
{{comment.name || 'Anon'}} said ...
{{comment.message}}