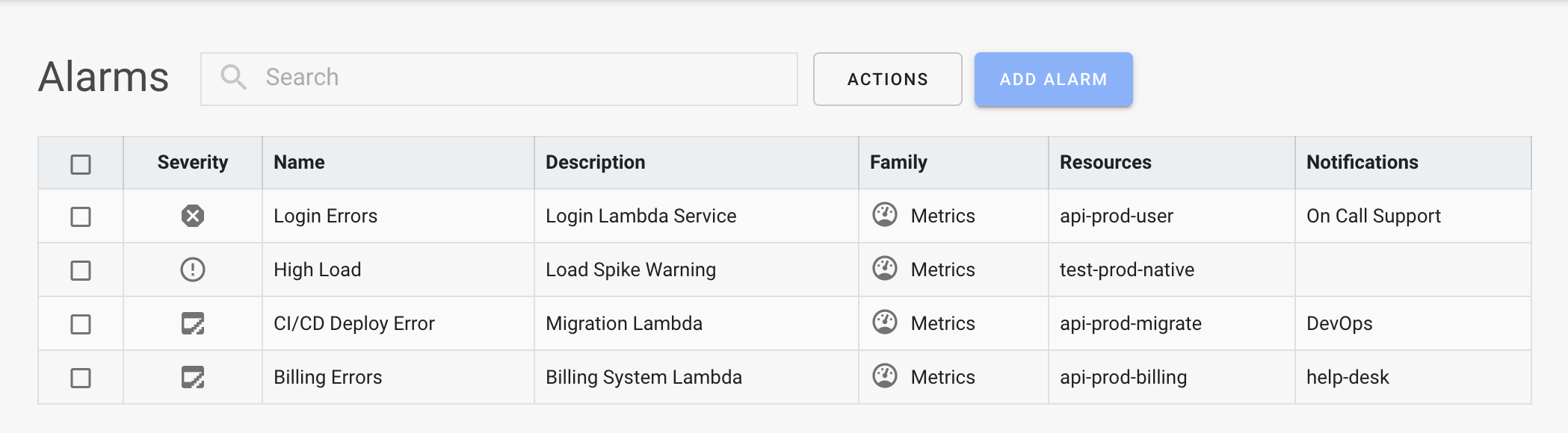
Alarms Overview
For effective observability of your serverless applications, you need both detailed monitoring and the ability to automate the deep and thorough health checking of your service. A set of alarms that will trigger when your application behaves unexpectedly, is an extremely effective aid toward such observability.
SenseDeep Alarms are automated rules that check Lambda, Log or EventBridge resources for specific conditions. These alarms can look deeply into your application events, logs and metrics to sleuth trouble. The alarms run 24x7x365 and will alert you at the first sign of trouble.
Alarms can monitor Lambda metrics such as Lambda duration, errors, invocations, concurrency or throttles. Alarms can monitor any log event data from a Lambda log group or indeed any application log group. Alarms can also monitor EventBridge events (nee CloudWatch Events) and detect specific events of interest.
Some serverless monitoring solutions only track CloudWatch metrics and do not have the ability to trigger alerts based on application log events or EventBridge events. SenseDeep Alarms provide coverage of both high-level metrics and specific application log data in real-time.
Alerts
SenseDeep Alerts are created whenever an alarm rule is triggered for a specific resource. When an alarm triggers, it generates an alert with full details of the resource and event that caused the alert.
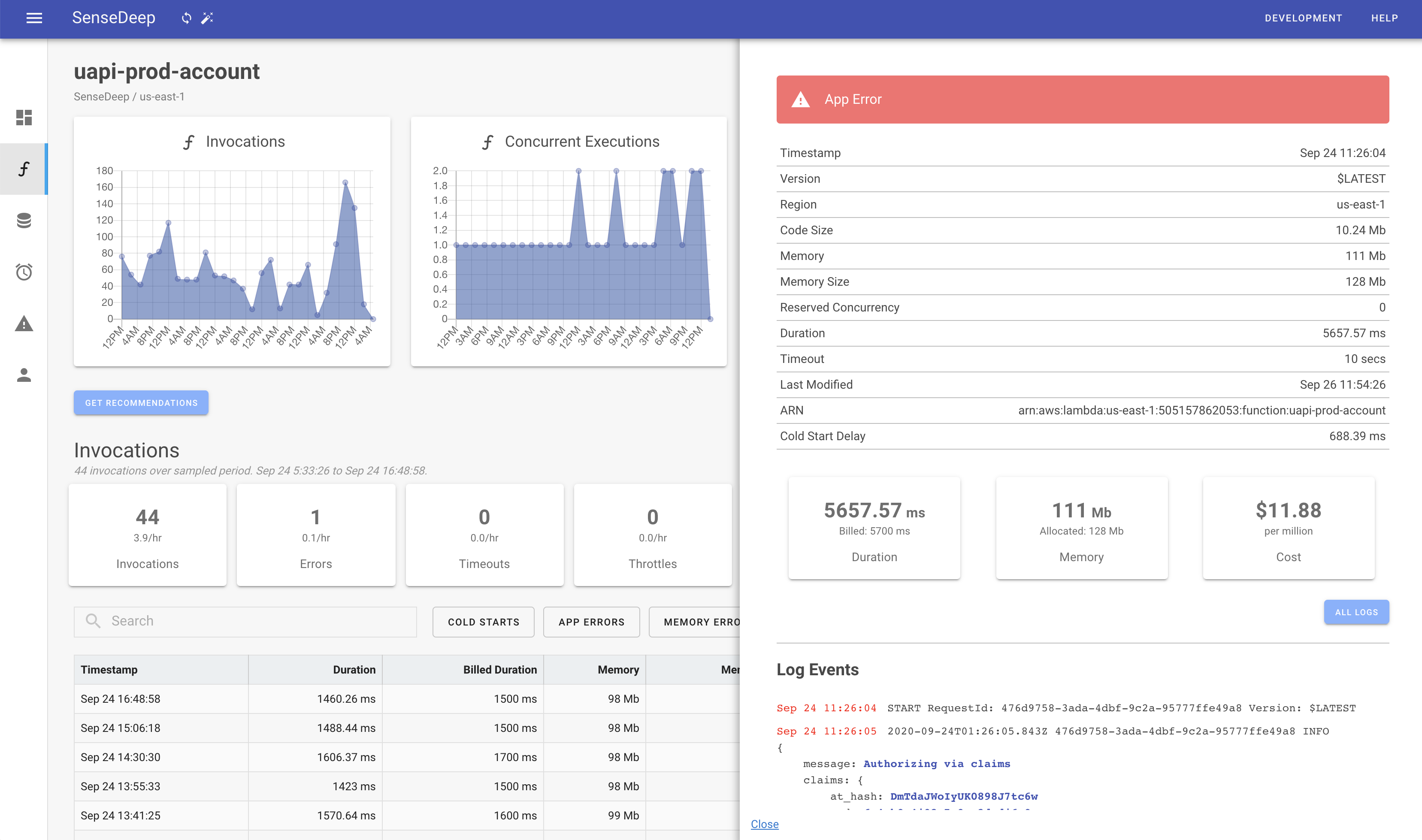
Alerts are displayed in the SenseDeep console and a single mouse will display the alert with full context. From there, another click will jump to the isolated Lambda invocation with full invocation details and log entries.
Notification Channels
Alerts can optionally run notifications to inform you immediately of an issue with your service. SenseDeep supports a wide variety of notification channels including: Email, SMS, AWS EventBridge, Lambda and HTTP/HTTPS.
Alert notification messages include when the incident occurred, the Lambda or resource that triggered the alarm and clear context of the triggering metric or log event.
SenseDeep will aggregate redundant alerts for the same resource so you will not be deluged with repeat notifications. A notification will be issued for the first occurrence of the alert and will be suppressed for subsequent alerts for 24 hours.
Coverage
SenseDeep Alarms will detect and proactively notify you if:
- Any service is encountering application errors.
- An EventBridge events indicates an anomaly.
- Any Lambdas start throwing exceptions, timing out or enduring elevated cold starts.
- Lambda durations have spiked.
- And any custom condition you wish to alarm for.
SenseDeep Watcher
SenseDeep runs a single, extremely efficient Lambda function in your account called the SenseDeep Watcher. The Watcher ingests AWS metrics and logs with the utmost efficiency and speed. By colocating the Watcher in the same region and account as your logs and metrics, SenseDeep can detect and respond to critical issues faster than any competing service.
The Watcher will selectively subscribe to the log groups necessary to implement your alarms. Data will only be ingested as required by your alarms. If you don’t create an alarm for a log group, the data will not be ingested.
Once you have created an alarm and your application signifies an error by emitting a log event, the SenseDeep watcher will run immediately in your account to receive the log data and swiftly trigger any required alerts.
The Watcher is automatically notified of new Lambdas and changing tags so that as new Lambdas are created, they are tracked and managed if required for your alarms. You don’t need to manually subscribe new Lambdas or log groups.